
Delivering Files Faster
HTTP Caching
As a web developer, you might think that requesting a resource is a straightforward act: the browser requests a file and your server delivers it. But a lot of optimization potential comes into reach when we look at "HTTP Caching".
To take an example, let's look at how an innocent file (e.g. an image, HTML, CSS, or Javascript file) makes its way to a website visitor.
A File on Its Way to the User
Before making the way to the server to fetch a resource, the browser looks at its own, local cache: if the requested asset has been downloaded previously (on a previous visit or on a different page of your website), a roundtrip to the server might not be necessary. The asset is returned directly from the local browser cache - and both network latency and downloading data can be avoided. This is the best scenario, both for the visitor (because she gets the resource instantly) and for you (because your server is not burdened).
There are many possiblilities why a browser might not be able to deliver the asset from its cache: most obviously when it's the first time the user visits this website; but also because an already downloaded asset isn't considered "fresh" anymore. In such cases, the browser will have to start a request.
If a CDN or proxy is used, they might step in and respond to the request (only, of course, if they have the resource in their cache). Although this is not as fast as a response from the browser's local cache, it's still considerably quicker than bothering our web server with delivering the asset.
If CDNs and proxies are not involved or if the caching rules demand it, our web server is asked for the asset. If we're lucky, the server can respond with just a "304 Not Modified" header: we had to make the roundtrip to the server - but we didn't have to actually download anything, since the server told the browser to use what it already has.
In all other cases, the asset is simply requested from the server and downloaded in full to the user's machine. This means network latency, downloading (potentially lots of) data, traffic costs... in short: the worst case.
The important thing to keep in mind is that we have a lot of possibilities to prevent this worst case scenario from happening.
Let's talk about what we have to do to make caching possible and efficient.
HTTP Headers
Whenever a resource is downloaded, the actual file itself is only one part of the transaction: an HTTP header accompanies the file and carries important metadata, especially from a caching perspective.
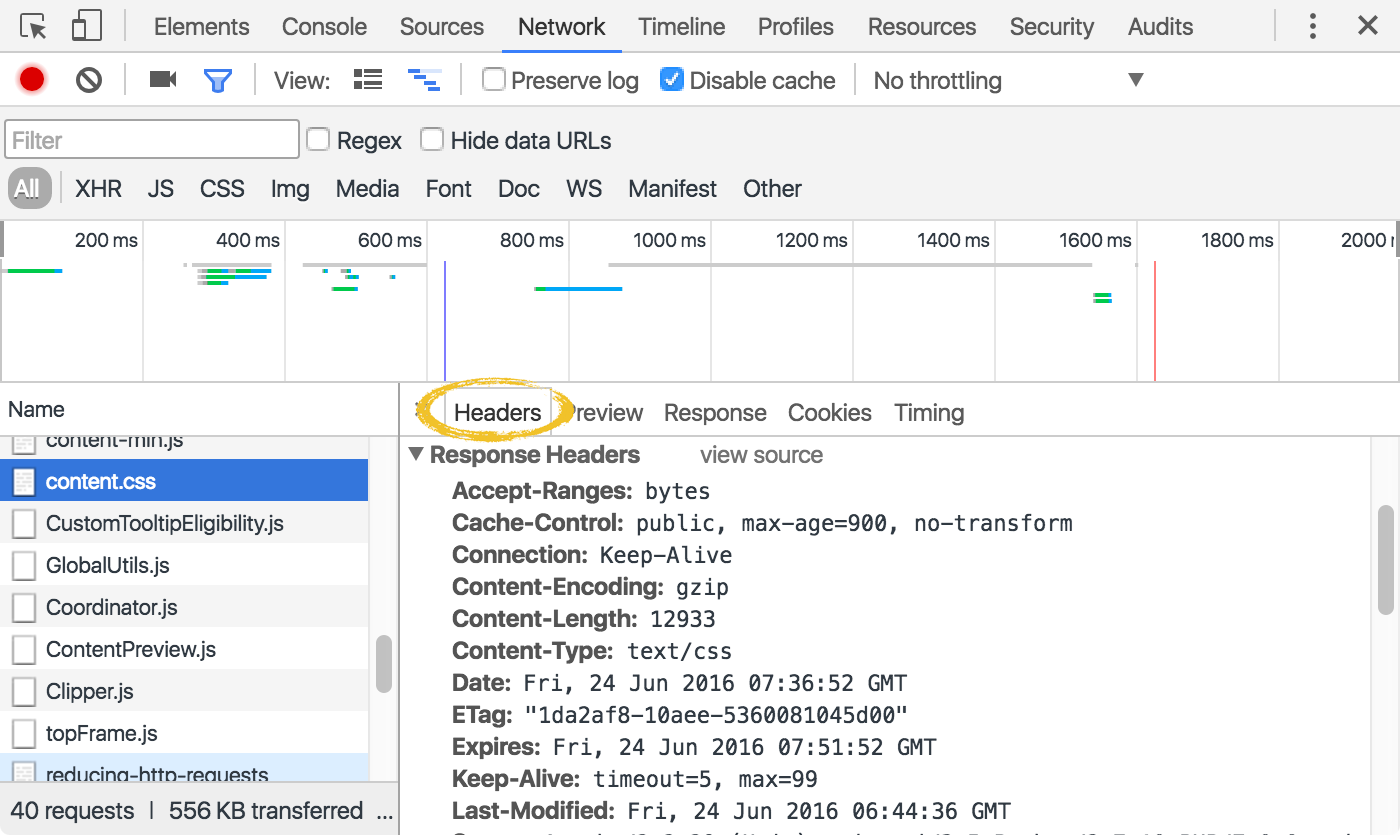
It's our job to provide the caching directives we want. But there is no golden rule for the "ideal" configuration - every project and possibly every file demands for its own caching policy that best suits the use case.
Let's look at two of the most important directives in detail.
Cache-Control
As the name suggests, this directive is all about control: you can define by whom, for how long, and under what conditions the file may be cached.
-
By whom: public and private
cache-control: publicMarking an HTTP response as "private" allows it to be cached only by the browser - not by any intermediate caches like proxies or CDNs. This is perfect for data that is highly personal, like in a social network application for example.
On the other hand, marking it as publicly cacheable allows it to be cached by "anyone" (browser, proxies, CDNs) and under "any" circumstances (even when HTTP authentication is involved). Since other directives like "max-age" (see below) implicitly set the cacheability, the "public" keyword is seldom necessary. -
For how long: "max-age"
cache-control: max-age=86400This directive, very simply, determines for how many seconds the response may be reused on subsequent requests. For example, by setting it to 86400 (60 seconds x 60 minutes x 24 hours) the browser may use the cached resource for 1 day after the initial request was made.
-
Under what conditions: "no-cache" and "no-store"
cache-control: no-cacheThe "no-cache" directive is a bit misleading: responses marked this way may very well be cached; but the browser must ask the server to make sure that no newer version of the resource has emerged in the meantime. This means that a roundtrip to the server will definitely occur - but at least no data will be downloaded if the resource is still "fresh".
With the "no-store" directive, on the other hand, all caching is forbidden: the browser has to request and download the file from the server every time.
It probably goes without saying, but you can of course combine these directives, e.g.:
cache-control: private, max-age=31536000ETag
We've mentioned the "freshness" of a resource a couple of times already: if a resource hasn't changed, there is no reason why we should download it again if we've already downloaded it on a previous request. But how can we know if the resource has changed or not? The "ETag" directive helps us with this question.
When the server delivers a resource, it can include an "ETag" validation token - essentially a hash of the content. If the file's content changes, this validation token will also change. The other part of this equation is the browser: it automatically sends out a file's ETag if it has received one on the last request. Thereby, the server can see if the client has the latest "version" of the file - and can then return a simple "304 Not Modified" header.
A roundtrip to the server occured in this case, but we didn't have to download any actual data.
Configuring Your Server
Carrying all of those "ETag" and "Cache-Control" directives into effect is (thankfully) done by the browser. We "only" have to make sure that our server includes the appropriate headers when issuing HTTP responses.
The actual configuration values, of course, are different for every web server. Thankfully, a couple of smart people have compiled a set of best-practice configurations for all the major servers: https://github.com/h5bp/server-configs
Additionally, the details of such a configuration depend on the type of project: different files in different scenarios might demand for a different caching policy.
However, before you configure yourself to death, you should consider the following caching strategy. It might be too simple for some specific needs; but in many cases it makes for a very simple yet effective caching strategy.
URLs are Identifiers
When putting caching into practice, keep in mind that the browser identifies a resource by its URL. Especially the reverse is important for us: if a resource gets a new URL, the browser considers it a different resource and will not deliver it from cache but instead download it fresh from the server.
This can make for a very simple yet effective caching strategy:
- By default, you can cache rather "aggressively" and have your resources expire in the far future (say, a year from now). This is done by marking your resources with high "max-age" values:
Request: about_v1.js
Response: Cache-Control: max-age=31536000- If you need to "invalidate" a resource (meaning you want to make sure it's downloaded fresh from the server because it has changed), you can simply give it a new name (and thereby a new URL).
Request: about_v2.js
Response: with its new URL, the file is not present in the cache and therefore loaded freshMany web frameworks use this tactic out of the box: they enrich the names of CSS and JavaScript files with a "version" number, transforming "home.css" into something like "home_344588.css". If the file's content changes, its identifier will change, too. When the file is referenced in your pages, the new identifier makes it an unknown resource to the browser - and is downloaded fresh.
This way, we don't have to deal too much with the intricacies of caching and still have a very robust and yet simple mechanism in place.
In a Nutshell
Using HTTP Caching
The fastest way to ship your resources is to leverage the user's local browser cache. HTTP caching is what makes this work!
- Make sure your web server is configured to deliver proper caching directives.
- Go with the simplest caching strategy that fulfills your needs.
Compressing Content with GZIP
Some optimization techniques take quite some effort to implement. On the other hand, however, there's also a lot of "low-hanging fruit": in this context, GZIP is like a banana that's already peeled and cut into bite-sized pieces for you - because it's so easy to implement. And yet its effect can be huge: GZIP will often reduce the size of your files by 60% or more!
But, before we get lost in excitement and praise, let's briefly talk about how this works.
Compressing Text-Based Content
GZIP is a compression algorithm that can be used on any stream of bytes. Although the details of its implementation are rather complex, its result is easy to understand: a file's content is highly optimized in order to reduce its size.
Smaller files, of course, mean that the user has to download less data. And downloading less data means our web pages can be displayed faster!
As already mentioned, GZIP can in theory be used on any type of content. However, it's important to know that it works best with text-based content. This makes it perfect for deflating your CSS, JS, HTML and XML files. Resources that are already compressed using other algorithms, on the other hand, don't benefit from (an additional) compression with GZIP. Using it for most image formats, therefore, is not recommended.
Enabling GZIP Compression
The best part about GZIP is that you as a developer have to do almost nothing: On the remote side of things, your web server is perfectly capable of compressing files. And on the client side, any modern web browser knows how to deal with compressed resources, too.
All we have to do is make sure our web server is configured to serve compressed resources.
Just to give you an idea, this is a (shortened and simplified) example of what such a configuration would look like for Apache:
<IfModule mod_deflate.c>
AddOutputFilterByType DEFLATE text/css
AddOutputFilterByType DEFLATE text/html
AddOutputFilterByType DEFLATE text/javascript
AddOutputFilterByType DEFLATE text/plain
AddOutputFilterByType DEFLATE text/xml
</IfModule>For complete and extensive configurations, have a look at the "HTML5 Boilerplate" project and their compilation of server configurations. The "gzip" sections in these configurations will provide you with a tried and tested setup.
Serving Resources from Multiple Domains
When downloading resources, browsers limit the number of simultaneous connections they establish. Typically, between 2 and 8 files can be downloaded in parallel - the rest has to wait. Therefore, even files that are small in size are relevant from a performance perspective. It doesn't matter if the actual download time wouldn't be long: the download won't start until a spot in the download queue is available. And these spots are limited.
These connection limits, however, are imposed separately on each domain. This simple fact gives us room for some optimization: for example, if your website runs on "www.mysite.com", you could use an additional domain like "assets.mysite.com" to serve your resources from. The browser will be able to establish 2-8 connections to each of these domains in parallel - and you thereby double the number of simultaneous downloads!
But before you get carried away and create "assets-1.mysite.com" through "assets-100.mysite.com": the advantage of parallel downloads will be mitigated by a DNS lookup penalty if you use too many different domains. Limit yourself to 2-4 additional hostnames and you'll get the best out of this technique.
In a Nutshell
Serving Resources from Multiple Domains
Browsers limit the number of resources they download simultaneously. However, since this limit applies to each domain individually, you can foster parallel downloads by requesting from multiple domains.
Using a Content Delivery Network (CDN)
How fast a resource is downloaded depends on many factors. An important one is geography: how far away from each other are the client and the server? If they are close to each other, latency will be small and the download will be fast. The further away they are, the longer the bits and bytes have to travel.
If your website has visitors only from a certain geographic area, you're best off renting your server hardware at a hosting company nearby. However, if your website has visitors from all over the world, you should think about using a Content Delivery Network (short: CDN).
A CDN is a collection of servers spread across multiple locations all over the world. The idea behind it is simple: when a user visits a website, always serve the files from a location as close as possible.
Let's make an example: If your CDN service of choice has a server in North America and one in Europe, then a visitor from France will be served by the European hardware while a visitor from the Canada will be served by the one in North America.
Behind the scenes, quite an amount of logic and (obviously) hardware is necessary to make this work. The good news is that all this is handled for you by the CDN service provider. You just drop plain old URLs into your HTML. From where your image, CSS, or JavaScript files are effectively served is then all decided by the CDN.
Using a CDN service offers a couple of benefits:
- Speed - Most importantly, a CDN reduces network latency by serving assets from a server as close to the user as possible. Problems can still arise, like the infamous 521 error message thrown up by Cloudflare from time to time. But when properly implemented and configured, CDNs can seriously speed up performance.
- Parallel Downloads - Remember that browsers limit the number of parallel downloads from each domain. With a CDN, your assets will be served from an additional, different hostname. That way, browsers can download more resources in parallel.
- Simplicity - Moving your static assets (images, CSS, JavaScript, PDFs, videos, etc.) to a CDN is very easy. Other optimization strategies might demand to change your whole application architecture. Although this might be perfectly sensible, using a CDN is a very cheap and easy first step that can improve things dramatically.
- Scalability - Putting your assets on a CDN relieves your server from delivering assets. Not having to handle these kinds of requests, it can deal with more traffic and users in general.
Here's a list of Content Delivery Networks that gets you started:
In a Nutshell
Using a CDN
Using a Content Delivery Network is an easy way to speed up your website: delivering assets from a location as close as possible to the visitor can make a huge difference.
Get our popular Git Cheat Sheet for free!
You'll find the most important commands on the front and helpful best practice tips on the back. Over 100,000 developers have downloaded it to make Git a little bit easier.

About Us
As the makers of Tower, the best Git client for Mac and Windows, we help over 100,000 users in companies like Apple, Google, Amazon, Twitter, and Ebay get the most out of Git.
Just like with Tower, our mission with this platform is to help people become better professionals.
That's why we provide our guides, videos, and cheat sheets (about version control with Git and lots of other topics) for free.